One of the most important features of the system is to provide the performance of each label at any point in time. This capability is achieved by testing the machine learning models against the manually labeled data records (true labels) using n-fold cross-validation.
In order to measure performance, the system provides several metrics explained below.
Confusion Matrix
Confusion matrix or error matrix is a tool widely used to perform error analysis understanding how the machine learning models are performing. The confusion matrix (image below) covers a binary scenario of classification, it is label X or it is not label X.
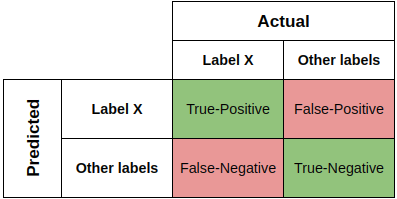
True-Positive (TP) - Correct prediction of the real label X.
False-Negative (FN) - Predicted as belonging to label X however, in reality, it doesn't belong.
False-Positive (FP) - Predicted as not belonging to label X however, in reality, it belongs.
True-Negative (TN) - Correct prediction as not belonging to the label X.
Based on the confusion matrix, we calculate several performance metrics which measure specify aspects of the system.
Precision
Precision is a percentage between 0% and 100% where the higher the better. This metric measures the percentage of correctly identified labels X from the total data records labeled with X.

Recall
Recall is a percentage between 0% and 100% where the higher the better. This metric measures the percentage of correctly identified labels X from all labels X in the dataset.

F-Score
F-Score is a score between 0 and 1 where the higher the better. This metric combines precision and recall in a weighted harmonic mean.
